The Cost of Code
October 2019 • permalinkThis is a talk that I presented at various software conferences and community events in 2019. Videos of versions of this talk are available from Beyond Tech 2019 and DotNext Saint-Petersburg 2019 – and check out my blog post Publishing Talks for a bit of background on how this was put together.

Hello, everybody, and welcome. My name is Dylan Beattie and I’m a nerd. I wrote my first web page in 1992, and I’ve been building software and web apps ever since. I’m the CTO at Skills Matter, I’m a Microsoft MVP, and I’m the creator of the Rockstar programming language – so if any of you ever wanted to become a rockstar developer so you can apply for all those sweet jobs on LinkedIn, check it out.

I’m a cis het English-speaking white guy, my pronouns are he/him, and yes, I am aware that means I live my life on the lowest difficulty setting. A brief content warning: this talk includes some discussion of road traffic accidents and aeroplane crashes; if that’s something any of you find difficult to discuss, feel free to leave or cover your ears or whatever works for you. I won’t be offended.
Right. I’m here today to talk about a very simple question: what does code cost?

Well… actually, it turns out that’s not a simple question at all. It won’t come as a surprise to anybody in this room that computer software – code – has profoundly affected almost every aspect of our lives. I was thinking about this a lot whilst I was putting this talk together; trying to work out if there’s anything I do in my own life that doesn’t somehow involve computer software. And I didn’t come up with much. I go out for a walk on Sunday now, and I’ll check the weather forecast on my phone and probably look at Google Maps. I cook dinner with a recipe on my iPad and music playing on my Google Home. I watch Netflix instead of TV, I listen to Spotify instead of CDs, I read books on a Kindle. I have apps for meditating and learning Russian and getting fit. I’ve come to rely on computers and software and the internet for just about every aspect of my life – and I’m sure many of you have as well. And every one of those apps and services and features that I’ve come to rely on was created by people like us, sat in front of computers, writing lines of code.

And I want to frame everything I’m going to say in this talk by saying that I think it’s great. I genuinely do. The ways in which the internet and modern software have transformed the world around us are nothing short of miraculous; we are literally surrounded, every day, by things which would have been unimaginable a decade ago. Remember in school, when teachers made you learn your times tables because ‘when you grow up you won’t have a calculator in your pocket?’ Well, Mrs. Marshall, turns out I have a calculator in my pocket pretty much all the time – which is also an encyclopaedia, a dictionary, a video store, a piano lesson, a Russian language teacher, a telephone, a post office, and a whole bunch of other things so advanced even the folks who made Star Trek never imagined them. I’m not here to tell you that technology is bad or evil or wrong, but I do believe there’s some really important questions that we need to ask ourselves – as individual developers, and as an industry – about how we manage the cost of all this innovation.

To start us off, I want to go back to the 1980s – the decade of FM synthesisers, white leather shoulder pads, and microcomputers. And specifically, I want to talk about Super Mario Bros. Super Mario Bros was released for the Nintendo Entertainment System in 1985. It was designed by Shigeru Miyamoto, and the game was written by a team of eight programmers working at Nintendo in Japan. It took about a year to develop – and that was it. The game was done. Finished. The total cost of the entire codebase was the salaries of the eight people who created it and a It was released in the US in late 1985, with a retail price of 25 dollars – and it would go on to sell over forty million copies.

The reason I chose Super Mario Bros is because I think it represents a very rare example of code as a clear, unambiguous asset. Like most consoles of the time, the Nintendo Entertainment System didn’t really have any kind of operating system. The code was programmed into a 256-kilobyte ROM cartridge and ran directly, natively, on the hardware. The hardware was a fixed target – the 60 million or so Nintendo Entertainment Systems sold around the world were to all intents and purposes identical. There was no operating system, no runtime, no standard library – and certainly no way to install patches or downloadable content after the game was sold. It had bugs, and they stayed there. That codebase cost nothing to maintain, and ended up generating nearly a billion dollars in revenue.
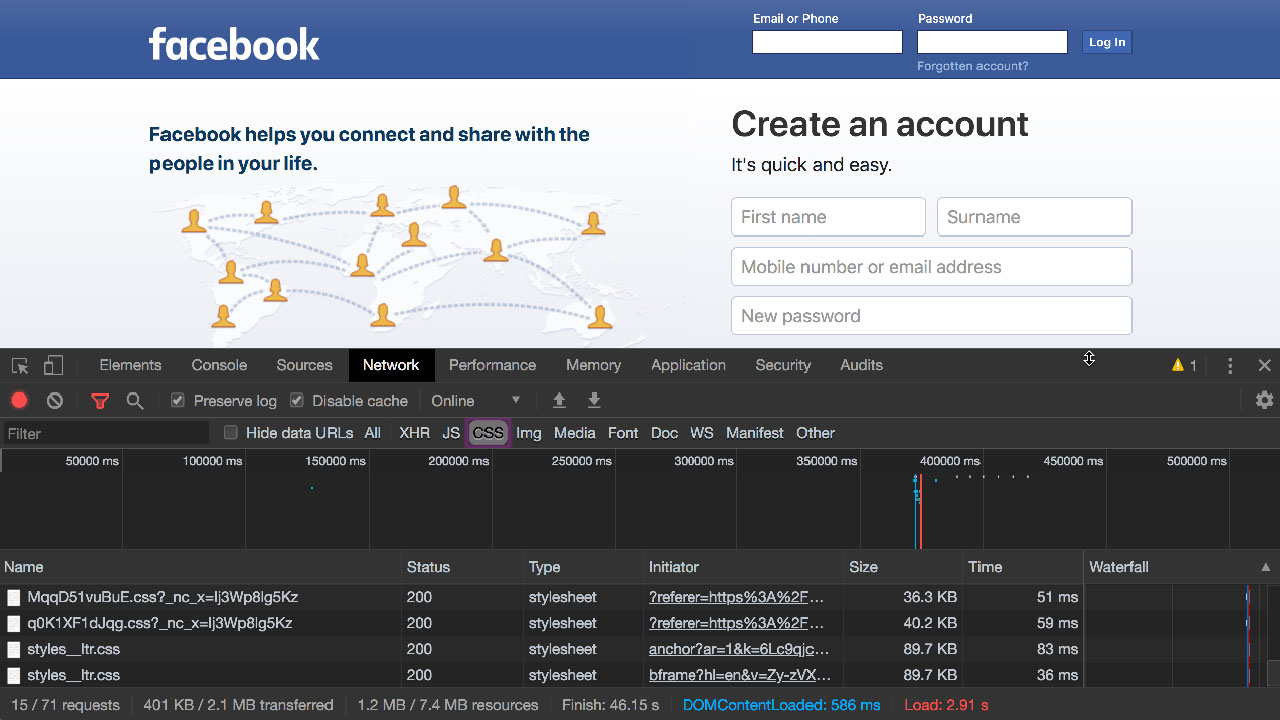
Unfortunately, though, most of us don’t get to write code once and then sell 40 million copies of it for 25 dollars each. Facebook’s main landing page uses around 350 kilobytes of CSS. Facebook gets roughly a million visitors a minute, so if Facebook could charge as much for code as Nintendo charged for Super Mario code they’d be making 36 billion dollars a day – just for CSS.
Now, that Super Mario example lies at one end of a spectrum. Nintendo paid some developers to write some code, they took that code and they sold it for a huge profit. But it’s entirely possible that, in purely financial terms, Super Mario isn’t even close to the most profitable code ever written – because they still had to pay developers to write it. What if the software itself was… free?

The whole concept of free software dates back even further than Super Mario; in fact, the idea of free software is older than the idea of paid software. The hacker culture of the 1960s and 1970s was built around sharing source code – which wasn’t hugely controversial in an era when computers themselves were rare, incredibly expensive, and access to them often restricted to the scientists, researchers and engineers who built them in the first place. After all – why would you even think about selling computer software when your lab has the only computer in the world capable of running it? It wasn’t until the late 1970s, when companies began distributing software as compiled binaries and refusing to share the source code, that the idea of ‘free software’ started gaining traction. And since we’re here to talk about cost, it’s important to appreciate that there’s more than one kind of freedom. We’ve historically talked about software as being in ‘free as in beer’ – meaning you didn’t pay money for it – and ‘free as in free speech’.
Now, when you go to your boss and say you want to use a new tool or a new framework on one of your projects, they’ll invariably ask ‘what does it cost?’ – and every place I’ve ever worked, they mean ‘money’. And it’s much, much easier to get approval to use tools and libraries when they’re free as in beer. But just because something doesn’t cost money doesn’t mean it’s genuinely free.

Free beer seems like a great idea, right? You ever been to a wedding? Free alcohol is a great idea until Uncle Harold gets roaring drunk and starts a fight with the bridegroom. And it doesn’t take much imagination to conclude that the widespread availability of free beer would lead to all sorts of public health problems, violence, alcoholism, liver disease, obesity. Perhaps asking what something costs in financial terms isn’t actually the right question.
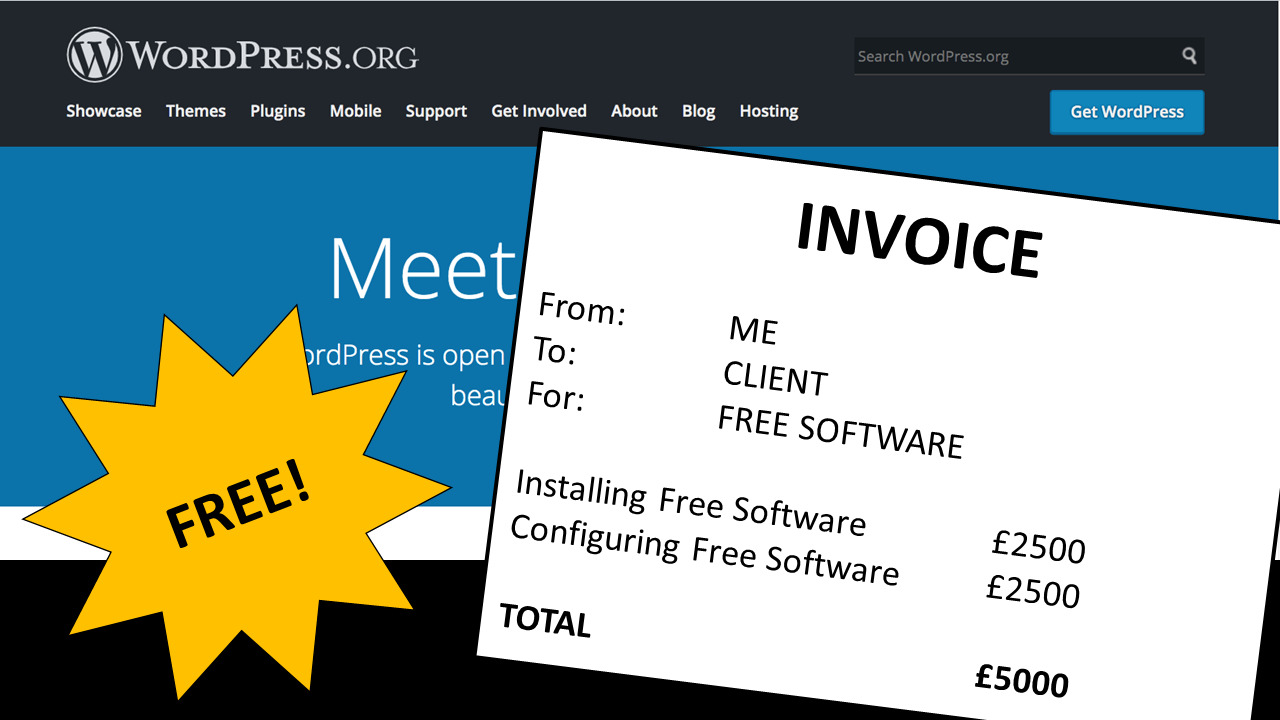
But the other kind of free that people talk about when it comes to software doesn’t really fit the bill either. Free as in speech. In other words – no restrictions are imposed on what you can do with it. You can share it, edit it, integrate it with your own code, maybe even sell it. And as crazy as it sounds, there are people out there who will pay good money for free software.
Original artwork by Dylan Beattie
When you set up a Wordpress site for a client, you’re often not actually writing any new code at all – but installing and configuring it takes generic ‘free code’ that anybody can use, and creates value by refining that code into a website that a client actually wants to use. And you think “hey, this is cool! I’m literally getting paid for free software!” That’s actually how a lot of us got started out as professional developers.
Original artwork by Dylan Beattie
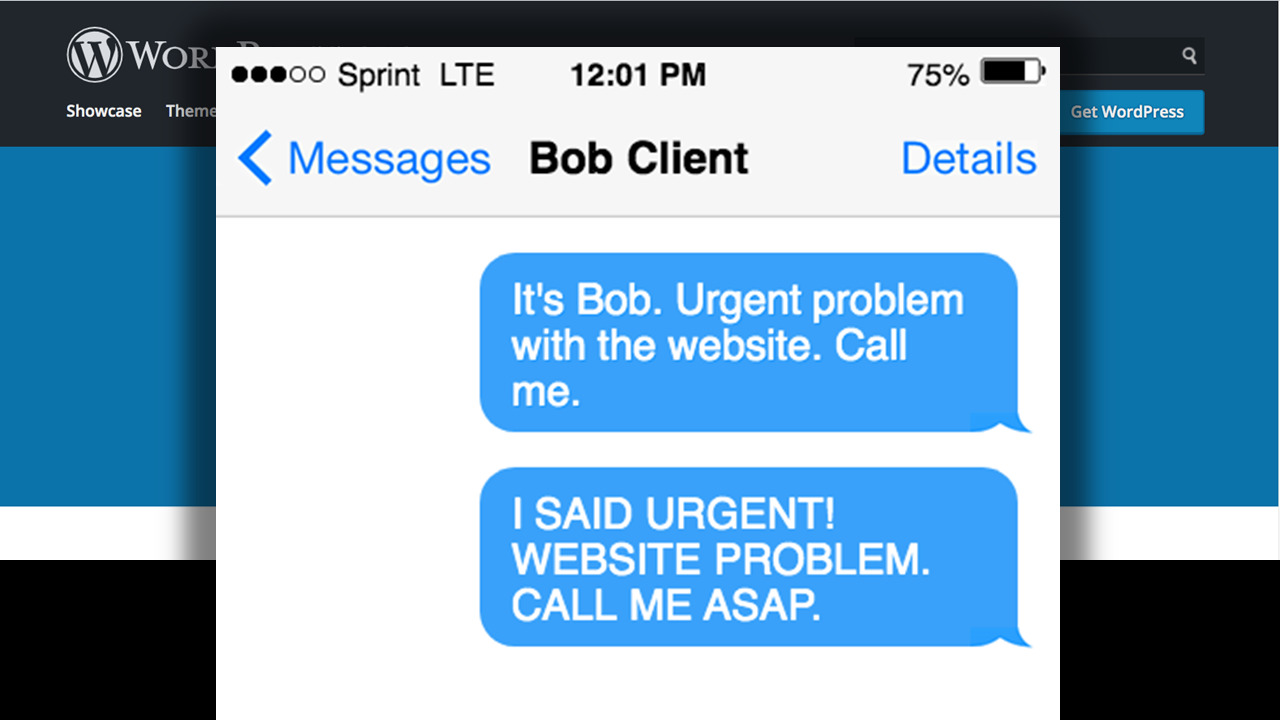
And then… a few months later, you get that email. You know the one. ‘Problem with website URGENT’. And a couple of panicked phone calls later and a bit of troubleshooting, you work out that the client’s site has been hacked.
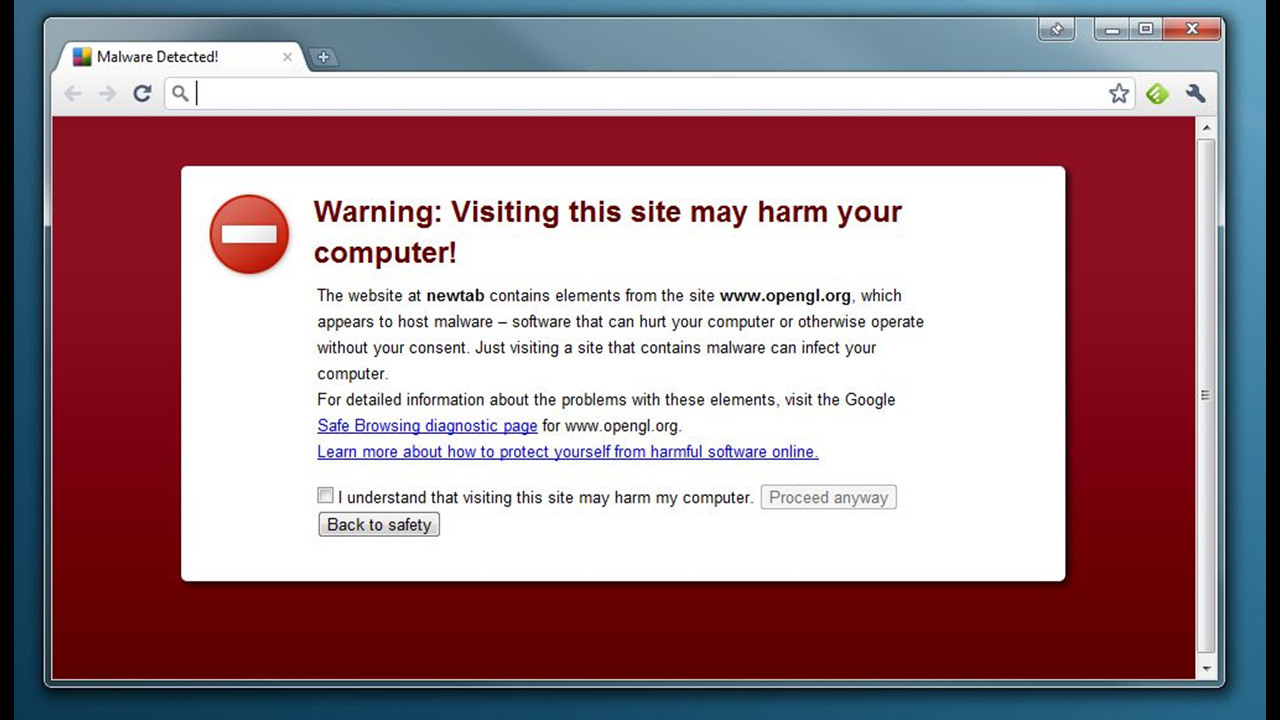
Somebody has used an unpatched security vulnerability, taken control of their site and replaced every page with a bunch of nefarious JavaScript that’s turning all their visitors’ web browsers into bitcoin miners. Now, at this point, explaining to the client that WordPress is free software and comes without any warranty really isn’t going to help. It’s not free to them, because you took their money – remember? And being free-as-in-speech doesn’t help either – just because they have the legal RIGHT to modify the software to patch that security vulnerability doesn’t mean they know how to do it, or even where to begin. They probably don’t even know what WordPress is – as far as the client is concerned, they bought a website from you, it’s turned out to be defective, and you’re responsible for fixing it. For free, of course.
But there’s another kind of freedom I want to talk about. Freedom from anxiety. Freedom from responsibility. The freedom to walk out of your office on a Friday afternoon and know that you’re not gonna get a panicked phone call or WhatsApp message on Saturday afternoon about another ‘urgent’ software problem. The freedom to enjoy your time off, have a beer, sleep late, go to the beach, ride bikes… you know. Free as in a ‘free weekend’.

Edward Snowden on the cover of WIRED magazine, August 2014.
Beer glass: Marco Verch / CC-BY 2.0.
Sunset: Richard Rydge / CC BY-NC-ND 2.0
The problem is that modern software development has embraced the power of free software and package management and code reuse to the extent that we don’t ever really stop to think about it any more – it’s just how software gets built. Whether you’re installing Ruby gems, or npm packages or NuGet packages, the first step in developing almost any software application here in 2019 is to install a few dozen megabytes of open source libraries and frameworks from the internet.
There is a framework called React, that originated at Facebook, which has become extremely popular for building rich client applications in JavaScript. Using React, you can accomplish in a few hours what would probably have taken a couple of weeks to do by hand. It’s popular with web developers, and it’s also widely taught at coding boot camps. And like a lot of developers, a while ago I figured I should take a look at React and see what all the fuss was about. I opened up the reactjs.org site, and poked around the documentation until I found this:
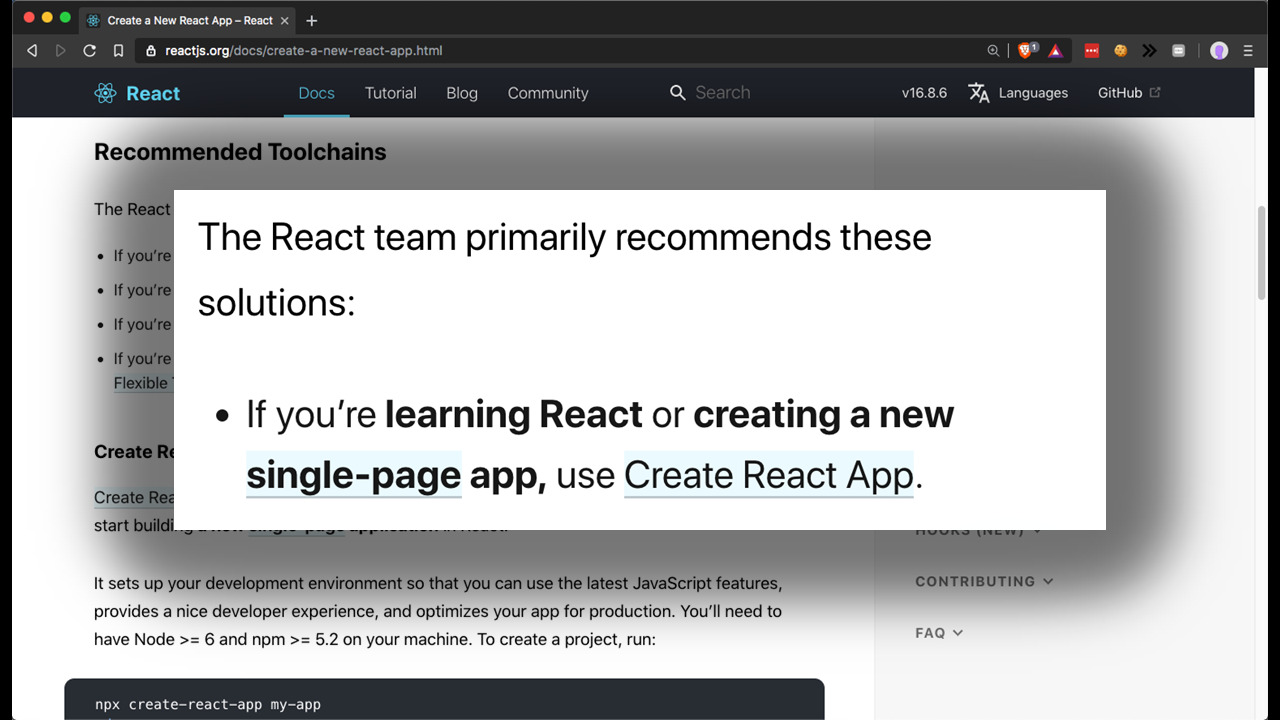
So, I downloaded it, and I ran it, and I watched as it ran off and installed a whole bunch of things, and when it was finished, voila - I had a new project on my laptop. Now, one of my go-to tools for exploring an unfamiliar codebase is a thing called cloc – stands for ‘count lines of code’. So I downloaded create-react-app, and ran it, and then I ran cloc on my new React application… and discovered that it contained around 1.5 million lines of code.
$ create-react-app my-react-app
— Dylan Beattie 🇪🇺 (@dylanbeattie) February 20, 2019
$ cd my-react-app
$ cloc .
Before you even open a text editor, your project contains 1.5 million lines of code. Most of it contributed by volunteers and enthusiasts. No formal review or release process.
This is 'normal' in modern web development. pic.twitter.com/VMl7IZuWFu
So, thinking this would probably provoke some interesting discussion, I shared that on Twitter. But I was very careful not to explicitly say whether I thought it was a good thing or a bad thing. The responses to that tweet were pretty much a 50:50 split between people agreeing with me that this was wonderful and amazing, and people agreeing with me that this was terrible and disastrous.
And as several people (including Dan Abramov, one of the core React maintainers) were quick to point out, what create-react-app is actually doing here is it’s installing an entire development ecosystem. You can write a React app yourself, in notepad, in about five lines of code. And it works – but it only works because when you ship those five lines of code to your user, you’re including another 23,000 lines of JavaScript code that you didn’t write.
Now, here’s the thing. I believe it is impossible to develop any kind of computer software in 2019 without trusting somebody else’s code. When Nintendo wrote Super Mario back in the 1980s, it was still possible for a single developer to understand every single detail of their system – hardware, software, op codes, interrupt levels, everything from memory location of the audio files to the voltage levels on the joystick port. Those days are gone, and they are not coming back. When we build software now, we have no choice but to rely on code, libraries and modules created by other people.

Your app relies on Entity Framework, and the Entity Framework relies on System.Linq, and System.Linq, is built on top of .NET Core. And, yeah, here’s WebForms over here…

Now, you could say that you’re not prepared to take that risk. You could insist that your team write your entire application themselves, by hand. And if you’re working in certain extremely high-risk applications – aerospace, healthcare – that might be justifiable. But for the vast majority of us, if we decide we’re going to build responsive rich client web apps by hand, we’re going to discover three things. One – developers absolutely love building frameworks. There is nothing so pure as the joy of spending several weeks creating general-purpose solutions to problems that you don’t actually have yet. It is WAY more fun than solving actual problems. Two – building frameworks is stupidly hard to do well, and a project like React actually attracts a lot more experienced JavaScript engineers than you’ll be able to hire. And three – your clients are not interested in paying you to reinvent the wheel. They’ve gone with the agency across the street now, who kicked off with create-react-app on Monday morning and had an MVP running in production by the end of the week. Or Angular, or vue.js – doesn’t actually matter. The point is, you don’t really have a choice.
Accepting dependencies on third-party code, and trusting that code, is a non-negotiable cost of creating modern computer software. Only once you’ve accepted that can you actually make some constructive decisions about how to work with it.
That code could be the Ruby gem that you’re using to upload photographs, or the JavaScript carousel that’s running on your homepage. It’s the stuff you didn’t write, but it’s part of your codebase and it’s running on your infrastructure. And it can bite you in a couple of different ways. First – it might have bugs in it.

Now, I am consistently impressed, and extremely grateful, that the open source community as a whole maintains what is generally an extremely high level of quality in code that is effectively maintained by volunteers and given away for free, in every sense of the word. But bugs happen, and if you are accepting a dependency on open source software as part of your codebase, you are accepting responsibility for any bugs. Sometimes, these are massive bugs that affect the entire industry. There’s a famous saying that originated with Eric Raymond ‘given enough eyeballs, all bugs are shallow’ – but there’s also a corollary to this rule ‘given enough projects, all eyeballs are busy looking somewhere else’, and sometimes really significant bugs go unnoticed for a long time.

In 2014, news broke that a vulnerability had been discovered in the OpenSSL cryptographic library, which was used by literally millions of websites to secure customer information. Further investigation showed that the vulnerability had actually existed for nearly two years. Now, the open source community did an absolutely fantastic job of managing this disclosure; a fixed version of the software was already available by the time the vulnerability was disclosed, and they took the revolutionary step of giving the vulnerability a name – Heartbleed – and a logo, which hugely boosted the media coverage and public awareness of the vulnerability.
But OpenSSL is a hugely significant project that’s used by Google, Microsoft, Amazon, Apple, Redhat… there’s absolutely no shortage of people who were in a position to help, and no question at all that it needed to be fixed. That’s not always the case. There’s seldom a week goes by I don’t see at least one instance of somebody online who has found something they don’t like in an open source project and believes the project maintainers somehow owe them a solution.

Sometimes it’s a genuine bug that’s considered low priority. Sometimes it’s a particular scenario that the user thinks should be supported and the project maintainers don’t. Sometimes the project maintainers have just had enough of getting yelled at by strangers on the internet in exchange for all their hard work, and they’ve abandoned the project and walked away.
Now, the great advantage of open source software is that when this happens, you can at least get hold of the source code for that package, so you’re not completely stuck. And perhaps you can pay the project maintainers to help you out – whether that’s via some sort of formal support arrangement, or just hiring them to do a couple of days’ work for you. Perhaps you can pay somebody else to fix it. But if you’re depending entirely on the kindness of strangers to patch critical security vulnerabilities in your customer-facing infrastructure, you’re likely to have a bad time.

Maybe it’s not open source code, though. Maybe it’s code you paid for. Maybe it’s commercially licensed components, or something you hired an agency to write for you. There has long been a perception among a certain kind of manager that code created by commercial vendors is somehow better than open source code because it comes with a warranty… you know the kind of person I’m talking about? Well, some vendors are actually really good at this – they’re attentive, they fix things, they’ll have a new release within a couple of days that fixes your problem. And some vendors, most notably Microsoft, are now embracing a model where they publish many of their products as open source AND cover them with a vendor support agreement – so if you’re a paying customer, you can file a support request, they’ll fix it, and everybody benefits.
The point is, the code that you’re running is your responsibility, regardless of who wrote it. When that code makes money, that’s your money – and when that code causes problems, those are your problems. And code can cause problems in all sorts of unprecedented ways. In early 2019, a doctor from Leicester tried to apply online for a Barclaycard and got this error message:
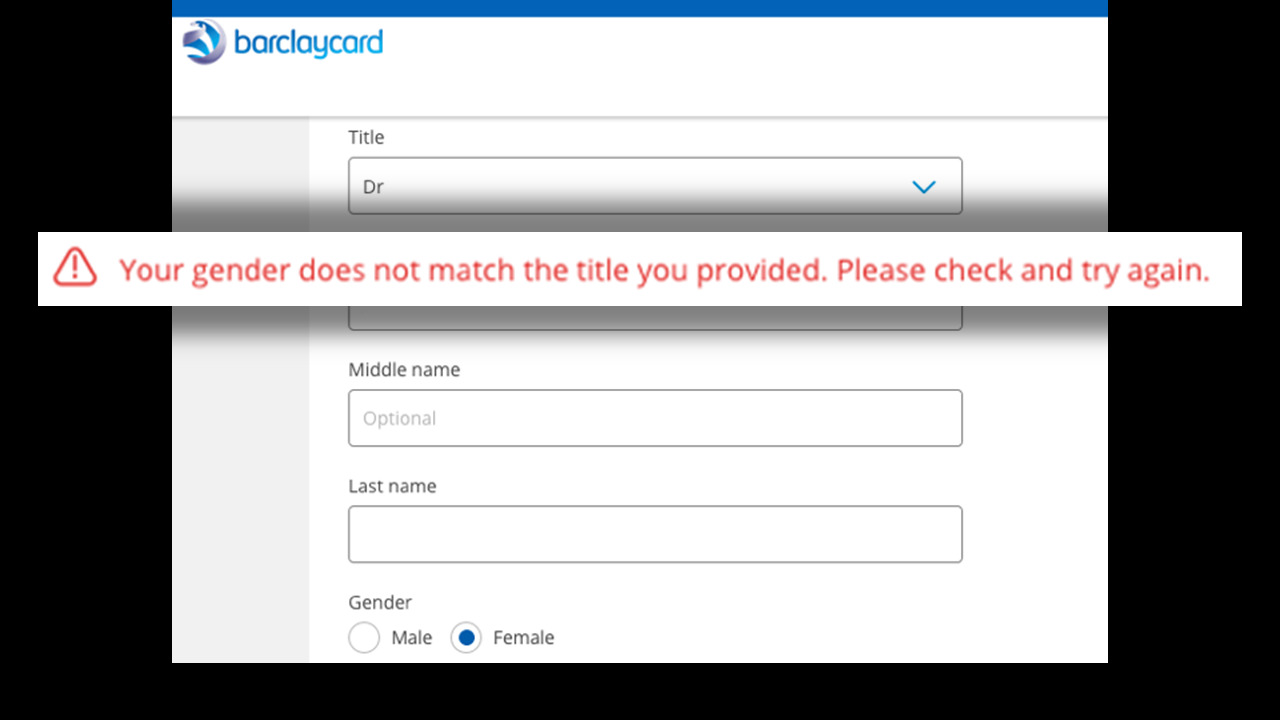
The application - Nikki - shared a screenshot of this on Twitter , and the internet picked up on this and it went viral – headlines in the media about “Barclaycard says women can’t be doctors”.
Hey @Barclaycard - it’s 2019! How come I can’t be both female and a doctor?! #everydaysexism #everydaymisogyny pic.twitter.com/MJ5rqR17DP
— Nikki (@_hurricanenikki) March 17, 2019
It was, of course, nothing of the sort; it was a stupid bit of JavaScript that didn’t work if you filled out the fields in the ‘wrong order’. Or at least, in what the Barclaycard developers thought was the wrong order. Moral of the story – run your tests forwards, run them backwards, test your edge cases, and remember that your error messages are just as much a part of your brand identity as your press releases, and if you’re autogenerated them from regular expressions or relying on generic templates, you’re – yet again – accepting responsibility for something you didn’t create.

That’s just one of the many ways that code can go wrong – or at least, behave in ways you didn’t expect. But what if it doesn’t? What if you’ve hired that hypothetical team of 100% unicorn rockstars and shipped a codebase that is literally flawless? No bugs, no defects, every single detail has been polished until the whole thing is absolutely perfect? What could possibly go wrong?

Well, let’s start with the dependencies you’re never going to be able to control. Even perfect code needs hardware to run on, and from time to time, we discover vulnerabilities in the hardware itself. In January 2018, Intel went public with news of two security vulnerabilities codenamed Meltdown and Spectre. These exploits relied on branching behaviour in just about every processor chip on the market – desktops, laptops, mobile phones, tablets – and because the vulnerability existed in the physical design of the processor, there’s no way you could just patch one code module or update one system. Vendors fairly quickly released patches for the most popular operating systems and applications – but because the vulnerability was inextricably coupled to a particular feature of these processors intended to improve performance, in some cases the only way to fix the problem was to disable support those features, which actually slowed down the machines; Intel’s chief of security, Leslie Culbertson, reported a performance impact of up to 8%.
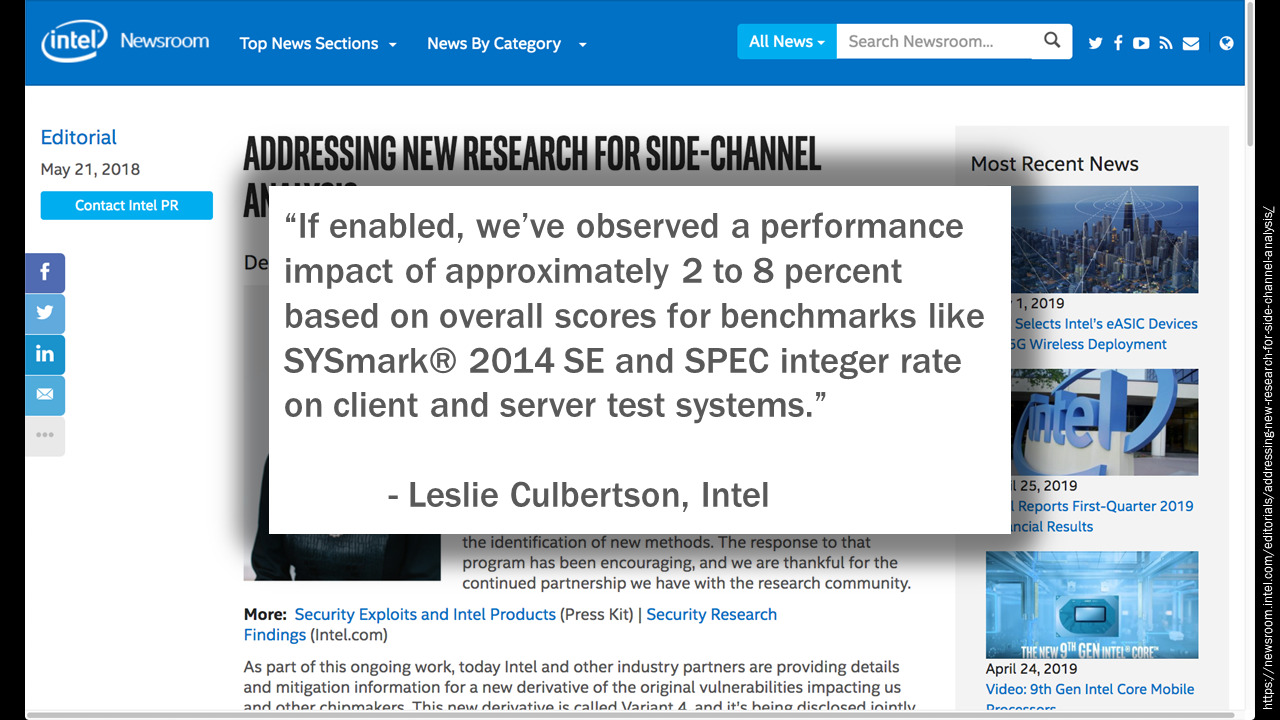
Now, most of the major vendors have now released patches for Spectre and Meltdown, but the real fix for it is… yeah, you guessed it. Buy a new computer. Intel and the other CPU manufacturers affected by the vulnerability have addressed it in their current and future hardware designs, so if you want perfect security and don’t want to compromise on performance, all you need to do is replace all your computers. Which is actually a lot easier than it looks for most of us, because if you’re hosting on Amazon Web Services or Google Cloud or Microsoft Azure, it’s probably already happened and you didn’t even know about it. If you’re one of those organisation that still has a rack of Dell PowerEdge servers in the basement, you’re in for a slightly more involved upgrade process… just remember to clip the power cables to something so you don’t lose them down the back of the rack, and when you get the new server out of its box, lift with the knees, NOT with the back.
But this brings us on to another cost of code. We’re all creating these amazing, immersive user experiences – virtual reality, augmented reality, machine learning, high-definition video and real-time streaming and any number of other things that are light years away from playing Super Mario until your thumbs hurt. And those experiences demand more from the hardware. Faster processors, more memory, more storage, more bandwidth. But that’s fine, because as an industry, we’ve always had this sort of tacit understanding that a new computer costs about a grand and in five years it’ll be scrap, so if our code is too demanding for our users’ hardware, we just need to wait a couple of years. That’s even reflected in the way UK and US tax law works – we accept that buying a new computer every five years is just a cost of doing business. And when it comes to mobile phones, it’s even worse.
The mobile industry has managed to convince us that we should all get a new phone every two years. By hiding the cost of the handset in expensive monthly contracts, it’s easy to overlook the fact that we’re often paying hundreds of pounds for a phone we’ll use for a couple of years, and then we start getting those text messages – you know… ‘Hey! Time for an upgrade!’ And we think ‘oh, man, maybe my phone is crap? What if I get mocked in the street and my children don’t respect me any more?’

I have an iPad at home that still works perfectly. iPad 2, bought in late 2013. It cost about six hundred pounds. It’s less than six years old. It works perfectly, and yet it’s pretty much useless. You see, nobody makes apps for a six-year-old tablet any more. Sure, it can run mail and Safari and stuff, but the apps that actually made it worth using – things like Netflix and BBC iPlayer and GarageBand – just don’t work any more. And they don’t work because they all require iOS 10 or higher, and you can’t upgrade an iPad 2 any higher than iOS 9, and the old versions of those apps – the ones that worked beautifully back in 2015 – are deprecated. The APIs and endpoints they relied on are shut down, decommissioned, and there’s no other way to install any apps on it because the iPad is very much locked into the walled garden that is the iOS ecosystem. So that iPad lives in a drawer, along with my iPhone 4 that doesn’t work any more because the battery has failed, my iPhone 5 that doesn’t work any more because the power switch stopped working… I think there’s even a couple of old Nokias in there somewhere.

Now, a modern smartphone is absolute masterpieces of engineering. Every single component and subsystem is a work of technical genius – signal processing chips, floating quantum gate semiconductors, lenses made from perfect slivers of artificial sapphire, high-definition microphones the size of a grain of sand. And to manufacture those components, you need very, very special materials.
There are eighty stable elements on the periodic table, and your phone uses more than sixty of them. To pick just one example: the magnets used in speakers and the vibration motor in your phone rely on a rare earth metal called neodymium. Neodymium is used to create incredibly powerful magnets – check out this video to see just how powerful:
Neodymium is remarkable stuff, but getting hold of it in the first place is challenging. First you’ve got to dig it up. The vast majority of the world’s neodymium now comes from China, from mines like this one:

The raw ore that’s dug out of the ground contains between 3 and 9 percent rare earths, with the rest a mixture of mud, rock, and radioactive elements like uranium and thorium. Then you’ve got to separate it – a complex process that involves sulphuric acid, gigawatts of electricity, and enough water to fill two Olympic-sized swimming pools every day. After processing a kilo of ore, you’re left with about 50 grams of neodymium and other usable rare earth metals – and a few litres of toxic, corrosive, radioactive sludge; a mixture of sulphuric acid, uranium and thorium. Which will remain lethal for about a hundred billion years – and it can’t be reprocessed, it can’t be recycled, and so all we can do is bury it – or worse. In China, near the town of Bautou on the edge of the Gobi Desert, there is a “toxic lake” – an “ocean of black mud […] made up of acids, heavy metals, carcinogens and radioactive material”.
And that’s just the neodymium. The rare earth element cerium, mined and refined using a very similar process, is used in almost all industrial glass polishing processes. The circuit boards in your phone contain tantalum, which is refined from an ore is known as coltan. Most of the world’s coltan deposits are in central Africa, where coltan is often mined illegally under horrific working conditions and the proceeds used to finance corrupt military regimes.
The battery in your phone contains around a gram of lithium – an element that’s fantastically good at storing enough energy to power your phone for a day or two, but which also occasionally gets a bit over-excited and decides to let all that energy out at once. The technical term for this is an ‘explosion’ – it doesn’t happen very often, but it does happen, as anybody who’s tried to get on a plane carrying a Samsung Galaxy Note 7 will testify. Now, the phone in your pocket contains tiny, tiny amounts of these elements. 30 grams of aluminium, one or two grams of lithium, 20 milligrams of tantalum. But to understand the ecological and sociological impact of that, you’ve got to understand the quantities involved.
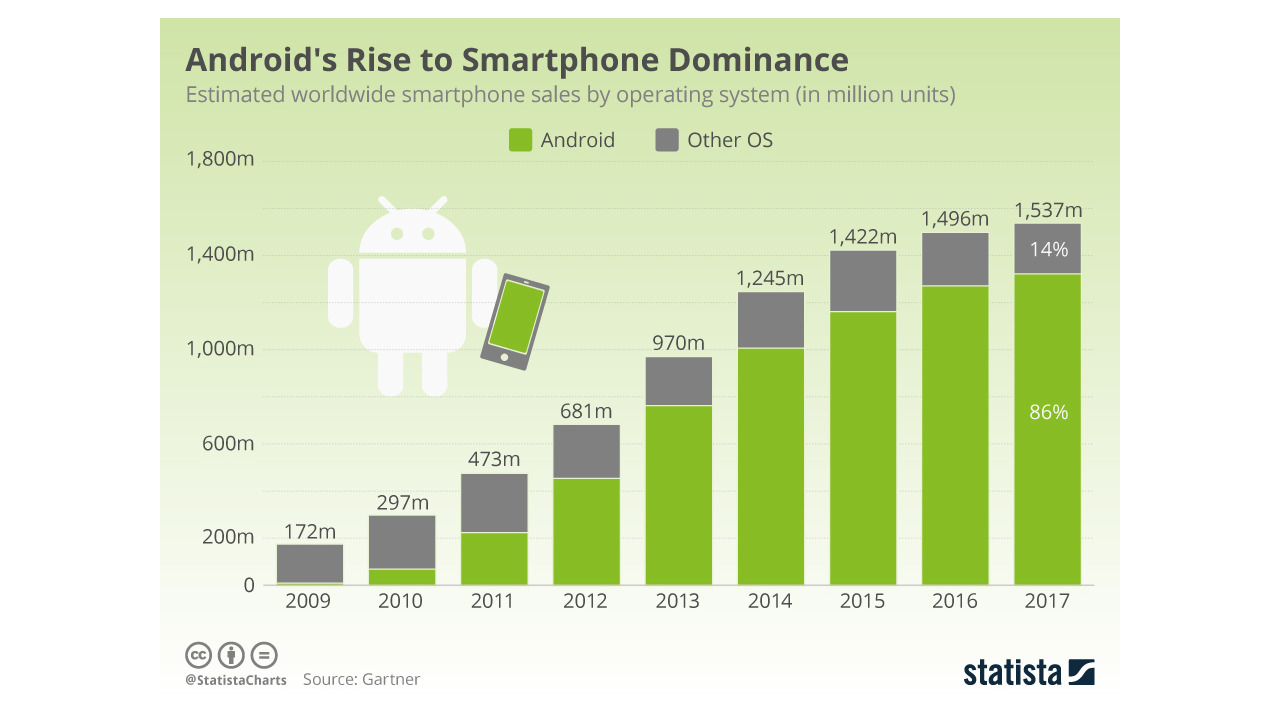
A Gartner report estimates that over eight billion smartphones were sold between 2009 and 2017, with six billion of those being Android devices. Google reported in May 2017 that there were two billion Android devices still in active use. So if we’ve sold six billion Android smartphones and two billion of them are still in use… what happened to all the rest? Four billion phones, with 2 grams of lithium in each phone’s battery – that’s nearly 8 million kilograms of discarded lithium. By way of comparison, the Eiffel Tower only weighs 7.3 million kilograms. Given the huge financial, environmental and human cost of extracting and refining those materials, surely they deserve better than to end up in landfill, or gathering dust in somebody’s desk drawer because they got a great deal on an upgrade?

Well, the good news is, we’re working on it. In a big way. In the UK, we’ve had legislation in place since 2013 to encourage the three ‘R’s – recovery, reuse and recycling – of waste electrical and electronic equipment. Internationally, consumer pressure is growing on manufacturers like Samsung and Apple to prove that their raw materials and components are obtained from sustainable, ethical sources that comply with rigorous health and safety policies and environmental restrictions. And industries all over the world are wising up to the fact that those piles of discarded electronics are a literal gold mine – a tonne of raw ore extracted using conventional mining techniques will yield five or six grams of gold; a tonne of discarded electronics can yield as much as 350g of gold.
But I still find it absolutely astonishing that people expect to replace their phone every two years. The current generation of smartphones is damn close to being as good as they’ll ever need to be. 4G is fast enough stream high-definition video in real time. We’ve got screens big enough that they barely fit in your pocket, made of pixels so small you can’t actually see them without a magnifying glass. Imagine if Apple, Samsung, Huawei announced that they’re committed to long-term support. That they guarantee the phone in your pocket right now will run every software update for the next five years? It’s not as far-fetched as it sounds. A company called Fairphone, based in Amsterdam, has recently announced plans to release a repairable, upgradeable Android smartphone with a five-year support lifecycle. Which I’m probably going to buy, even though I don’t need a new phone right now – which rather defeats the point of a sustainable phone – but hey, I promise not to buy any more phones for five years after that, OK?

It’s not just about environmental sustainability, though. For us software developers, this would mean that, for once in our careers, we actually got time to get REALLY good at something. Those folks back in the 1980s writing Super Mario? They didn’t have to learn a new framework every three months, or deal with a constant cycle of package updates that meant they spent more time resolving version conflicts than they spent writing code. They knew every detail, every instruction, every single last trick and technique to get the best possible performance out of that hardware.

Yeah, I know. It’s not going to happen. But I bet you if every coltan miner, neodymium refinery worker and factory assistant involved in producing your phone was being paid the UK minimum wage and entitled to healthcare and benefits, the cost of a new phone would go up so dramatically it would fundamentally alter the economics of the mobile phone industry… would you expect your customers to pay ten thousand euros for a new handset, or would you give the developers another couple of weeks to optimise their rendering code and eliminate some more pointless JavaScript so your app runs smoothly on the handsets that are already out there?

But even if we solved all these problems, and the whole world was running secure, performant, maintainable code on sustainable hardware, code still has a cost. And it’s the hardest cost of all for us to rationalise, because it’s the cost of code that does bad things on purpose. Code that was written, tested, absolutely satisfies the specification – and still ends up causing harm.

In May 2018, five executives from Volkswagen, the German car manufacturer, were charged with fraud in a German criminal court. Now, this is not some PR Twitter storm, or a corporation getting fined, or having to recall a product or refund some customers. No, all of those things have already happened. This is a group of people who are likely to be convicted of a criminal offence and be sent to prison for up to ten years – and all because of some computer code.

The code in question was installed on 600,000 Volkswagen cars sold in the United States between 2009 and 2015, and ‘millions more’ vehicles around the world. And the code worked perfectly, and it did exactly what it was designed to do: it detected when the car was being subjected to an emissions test, and modified certain parameters to cause the engine to behave differently than it would do in normal operation. Now, the whole reason we have emissions tests in the first place is to try to control the amount of toxic, dirty, dangerous pollutants being released into our atmosphere by cars. And somebody at Volkswagen decided that it would be fine if those engines released more dangerous toxic pollution than they were allowed to, as long as nobody got caught – and so asked their software engineers to deliberately modify the engine management system so that it would behave one way under test conditions, and do something different when it was being driven out on the street.

Now, I have no doubt that the people who made this decision did not actually write that code themselves. I also suspect that the engineers who wrote the code were only following orders, as the expression goes. But I find it remarkable that nobody spoke up about it. This isn’t some systemic failure attributable to edge cases and complex interactions.
The amount of code involved appears to be remarkably small. In 2017 a team of researchers analysed the firmware and presented their findings in “How They Did It: An Analysis Of Emission Defeat Devices in Modern Automobiles” – which showed that even a fairly cursory analysis of the code would reveal what it’s doing and under what conditions. There is literally a Boolean variable in the code, InjCrvstNsCharCor, that controls this behaviour. Now, I’ve reviewed a lot of code over the course of my career. Finding weird boolean flags and asking somebody what they do, and why, is practically a weekly occurrence. It would seem obvious to me that before too long, somebody working on that code would have found this variable, worked out what it did, and blown the whistle. But nobody did. That code was built, reviewed, installed on millions of vehicles worldwide, and wasn’t discovered until six years later.

That decision has cost the Volkswagen corporation over 20 billion pounds in fines and penalties. It’s caused irreparable damage to the company’s reputation and credibility. Five senior members of staff – well, former members of staff – are facing criminal charges for their role in the scandal. And a peer-reviewed study published last year in the United States set out to estimate the public health impact of the scandal: 45,000 disability adjusted health years, and 59 deaths. Because of some code. And every single person who knew what was happening and didn’t say anything is complicit.
But what happens when the developers don’t know what’s happening? What do we do when the code – good, solid code that behaves exactly as intended – becomes part of a systemic failure?

On 28 October 2019, Lion Air flight 610 took off from Jakarta airport in Indonesia. 12 minutes after take-off, the plane crashed into the Java Sea, killing all 189 passengers and crew. The phrase ’software problem’ appeared multiple times in the press coverage immediately following the incident. Just over four months later, Ethiopian Airlines flight 302 crashed shortly after take-off. 157 people were on board. There were no survivors.

The common factor in these two incidents was the aircraft model involved – the Boeing 737 MAX 8. That particular model of aircraft has now been grounded worldwide until the formal investigations into these accidents are complete, but there’s already a great deal of information available from multiple sources about the circumstances surrounding those crashes and the factors that might have contributed to them.
Now, I’m a software nerd. And an aeroplane nerd. I have two uncles who are pilots, I spend a ridiculous amount of time travelling, and I’ve been following this story with great interest. The aviation industry is incredibly good at learning from these kinds of incidents; processes are reviewed, aircraft are grounded, they have some of the most rigorous investigative procedures in the world, and it’s almost unheard of in modern aviation for the same thing to go wrong twice. Let’s start with a bit of background. The Boeing 737 MAX is basically a Boeing 737 with bigger engines and a few other relatively small modifications. Why? Range. Bigger engines means you can fly further, which means you can offer more routes. In 2013 Boeing’s main competitor, Airbus, introduced a long-range variant of their popular Airbus A320, and Boeing was losing sales to Airbus. The 737 MAX was a direct response to this.

Now, aviation is incredibly strictly regulated, and one of the things that’s regulated is which aircraft pilots are allowed to fly. This is known as the pilot’s type rating. It’s effectively a certificate saying that a particular pilot is qualified to fly a specific model of aircraft, commercially, with passengers on board. And as you can appreciate, if you’re running an airline, it’s normally a good idea if your pilots are allowed to fly your aeroplanes. Training pilots on new or unfamiliar aircraft is a costly and expensive process, so when an airline is looking to buy or lease new aircraft, it’s a huge advantage if those new aircraft are covered by their pilots’ existing type ratings.
So when Boeing designed the 737 MAX, they were trying to balance two conflicting requirements. One was to give the aircraft longer range, which meant bigger engines, more fuel capacity. The other was to keep the design sufficiently similar to the existing 737 aircraft that pilots wouldn’t need a new type rating. But it turns out those new engines on the 737 MAX were actually so big they wouldn’t quite fit under the wings.
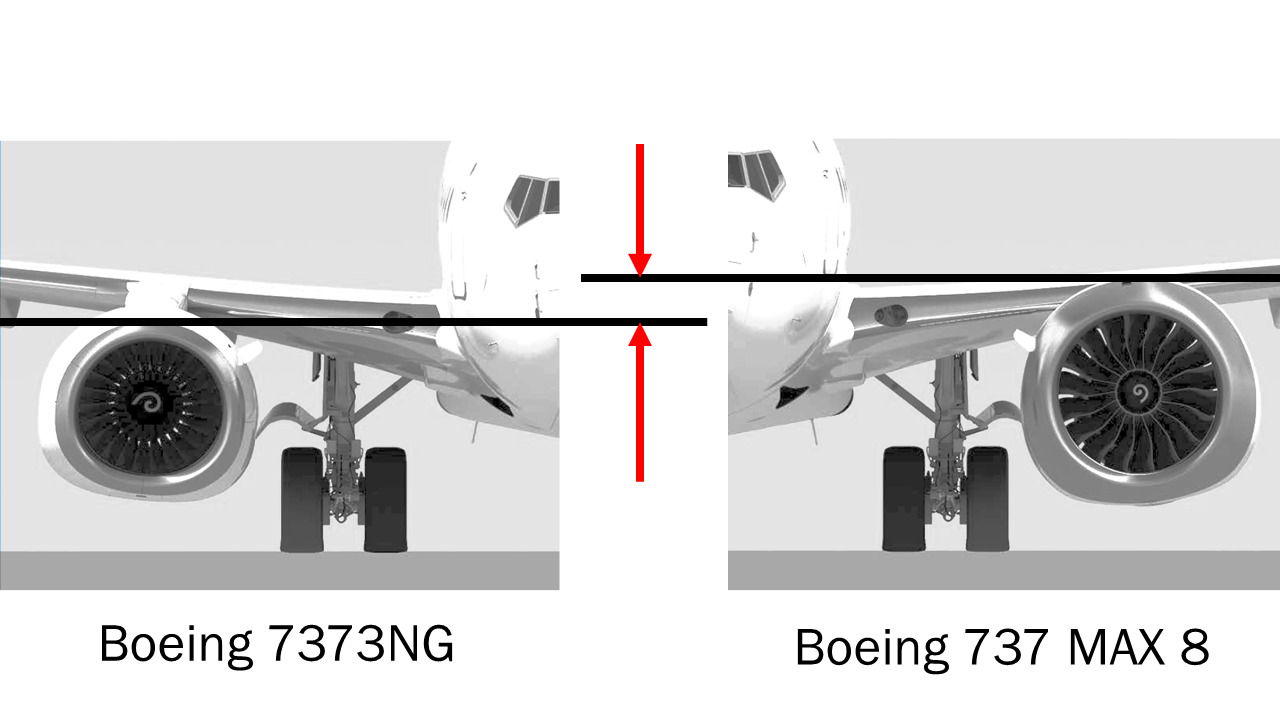
(Annotated to highlight differences in engine position)
They couldn’t redesign the airframe to make the wings higher, otherwise it wouldn’t have been a 737 any more, so instead they mounted those new engines a little further forward and a little higher than the old ones. And this is where it gets complicated. That new engine placement introduced handling problems – it meant that when you open the throttle, the aircraft had a tendency to stick its nose up in the air. And that’s bad, because if the nose goes up too high the plane is going to stall.
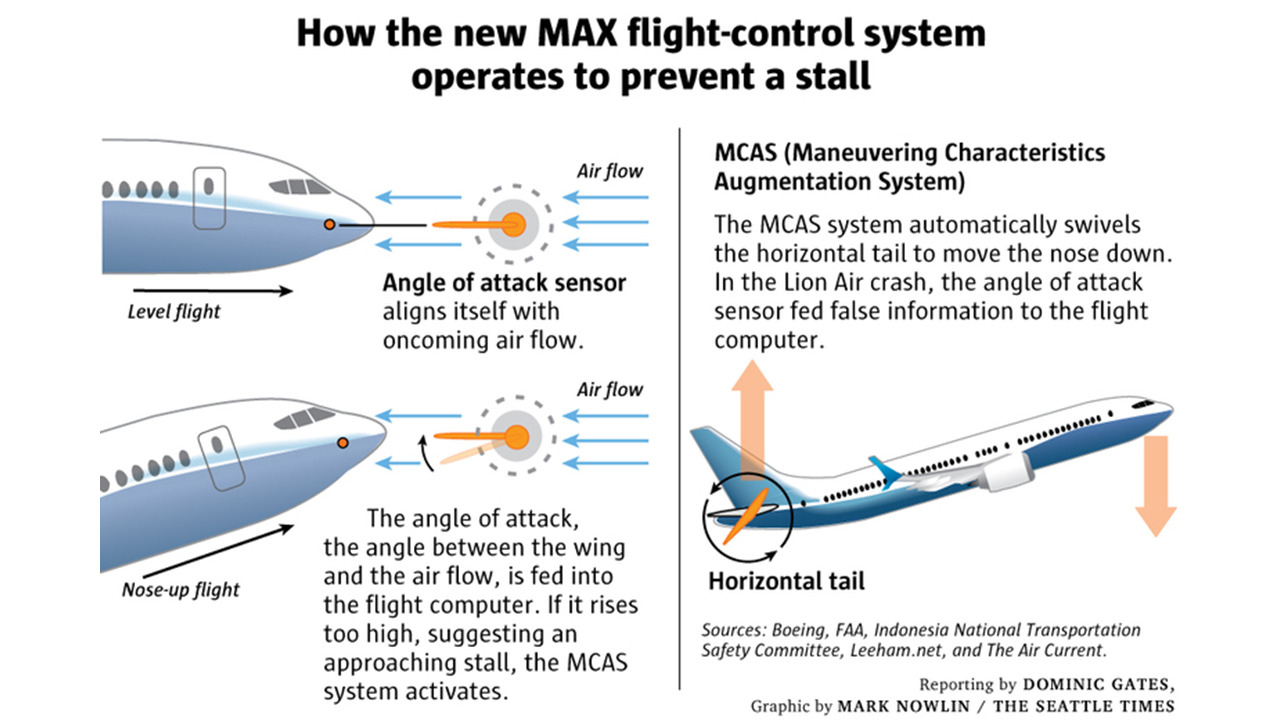
And so the solution to this was software. Specifically, a software system called the MCAS – the Maneouvering Characteristics Augmentation System. Like most modern airliners, the 737 MAX is a fly by wire aircraft, which means almost everything in the 737 MAX is a controlled by a computer. The pilot pushes the joystick, the joystick sends a signal to the computer, the computer controls the flaps, engines, control surfaces – pretty much everything. And by modifying the software running on the computer, you can actually change the way the aircraft responds to those signals – in this case, to make the 737 MAX feel like flying a 737.
So the bigger engines meant changing the engine placement. The engine placement caused a handling problem, and the software was intended to correct that handling problem. If the software detects that the plane’s nose is rising, it’ll bring it back down – automatically. And as far as we know, that software worked absolutely fine, and did exactly what it was supposed to. The problem is that software can only respond to input. The sensor that tells the computer whether the plane’s nose was rising or not is something called an angle of attack sensor. And it appears, tragically, that on both Lion Air flight 610 and Ethiopian flight 302, the angle of attack sensor malfunctioned. The software received input that said the plane’s nose was rising; it responded, as designed, by lowering the nose. Repeatedly. The pilots appear to have been unaware that this was happening – after all, it never happened in any of the other 737s they’d flown, and Boeing assured them that this was a 737 just like all the others. There were manual override procedures available, but the pilots were unaware of them or unable to implement them in time.

Now, unlike the Volkswagen emissions incident, you could never have predicted these tragedies from looking at the code. The code was fine. To call this a ’software problem’ is disingenuous at best. Software was what made this aircraft commercially viable in the first place – and the developers who created that software didn’t screw up.
But in this particular situation, the MCAS software is just one of the components, decisions and procedures that’s contributed to a systemic failure at every level. It’s raised questions about the aircraft design itself, the certification process for that aircraft, communications, pilot training procedures – and yes, software, and the role and accountability of software in modern applications. And we don’t have any answers yet. What happened with those two flights is a tragedy. We owe it to the people who lost their lives in those crashes to learn every single thing we possibly can, to act on those lessons.
But one thing that’s already apparent is that we cannot afford to treat software as a separate concern any more. In March 2018, in Tempe, Arizona, Elaine Herzberg was hit and killed by a self-driving car whilst crossing the street. The car was part of a test program run by Uber – a company whose use of technology has already seen them fall foul of regulators in cities all over the world, and who are investing huge amounts of money in developing what they hope will be the world’s first fleet of fully autonomous taxis. There are obvious questions of liability and accountability – although this particular incident was resolved by a confidential settlement and so there were no criminal proceedings that could have established a legal precedent.
Part of the problem here is a tendency to focus on hypotheticals. You’re probably all familiar with the trolley bus problem – in the event of an unavoidable collision, should a self-driving car be programmed to deliberately kill one person in order to save two people? Well, I have a drivers’ license, and I don’t remember that question being on the test – and when those kinds of incidents do occur, we have systems to handle them. We have emergency services, we have law enforcement, we have the courts, and we have the power to create rules and regulations in response to those incidents. But there are also much bigger questions around how autonomous vehicles are going to affect society, which are absolutely not hypothetical – they’re going to happen, and they’re going to happen soon.

Visualisation by Artem Smirnov and Vladimir Panchenko
www.behance.net/gallery/37932461/TRUCK-FOR-AUDI
You know what the single most common job in the United States is today? Truck driver. When you include long haul truckers, couriers and delivery drivers, there’s 3.5 million Americans who drive a truck for a living. And the reason it’s the most common job in the United States is that it’s immune to to the two biggest trends that affect employment figures – offshoring and automation. If you need to get a truck full of shrimp from San Francisco to Las Vegas, you can’t outsource it to China and you can’t get a computer to do it… yet. But what happens when you can? What happens when Uber self-driving trucks are plying the highways of the United States 24/7, stopping only to unload and refuel? What happens to the drivers? What happens to the infrastructure of truck stops and gas stations and maintenance depots that exists to support them?

The sociological impact of software doesn’t stop there. Democracy around the world is in turmoil. Here in the UK, we’re facing the biggest political crisis for a generation – not as a result of a natural disaster or aggression by a foreign power, but as a result of a controversial referendum organised by a democratically elected government. In the years since that referendum, information has come to light about an organisation called Cambridge Analytica, who – to put it very bluntly – appear to have used some extremely sophisticated social media campaigns to target very specific individuals with a campaign of misinformation and unsubstantiated claims in the run-up to that election. Individuals in key areas were identified, profiled, and targeted with personalised advertising intended to manipulate their vote. And it worked.
Political advertising in the United Kingdom is incredibly tightly regulated – there have long been limits on what newspapers, television and radio is allowed to say and publish in the period leading up to an election, and if those regulations are broken, there’s evidence. There’s a paper trail, there’s broadcast recordings. But none of those regulations has evolved fast enough to cope with social media, and to protect our democratic process in an age where you can show a specific advertisement to one person, once, and then it disappears without a trace.
Facebook’s home page has long carried the slogan “It’s free and always will be” – and sure, they don’t charge money. But as we’ve seen today, there’s more than one kind of freedom. The other catchphrase that’s famously associated with Facebook was their old engineering motto, “move fast and break things” – well, it wasn’t entirely clear that democracy was one of the things they were trying to break. Or maybe it’s just a side-effect. But the impact on our society will be profound and lasting, and it’s far from clear how we can hope to regulate digital media in the way that we’ve always taken for granted with traditional broadcasters and publishers.
I’m sure you’ve all encountered the trope of the high-powered executive who is not just ignorant of technology, but who actually wears that ignorance like a badge of pride. Somebody who is tasked with making decision that affect thousands of peoples lives, millions of pounds in revenue – who claims to be such an expert in their field that it more than justifies their seven-figure salary – but who still makes lame jokes about the fact they don’t really know how to use their own email, let alone understand the role that software and automation plays in those very business processes. But we cannot, and we must not, think of software as an afterthought.

This year marks the fiftieth anniversary of the Apollo moon landings. And yes, we should celebrate the anniversary of that accomplishment, because it remains one of the most audacious things humankind has ever done. But we should not just celebrate the six cis het American white guys who actually did it. We did that already. Let’s celebrate the half-a-million people who helped put them there. Engineers, mathematician, managers, doctors, janitors… and it’s only in the last ten years or so that we’ve started to hear their stories.

And in particular, let’s celebrate this person – Margaret Hamilton. Margaret led the software team that created the navigation systems used in the Apollo programme, fifty years ago. She was the first person to use the term ’software engineering’, and was a great advocate of something she called a systems view – that software was just one part of a complex system, and to understand the software, you had to understand the entire system. And perhaps that’s something we can aspire to. We call ourselves developers, hackers, coders – but if we really want people to regard software as an engineering discipline, that starts with us. We have to take that systems view – not just look at our code in terms of unit test and integration tests, but as part of a connected whole. To see our code as part of a huge global system that includes elections and transatlantic cables and coltan mines and airline pilots. We must help people understand – not just the other people at the JavaScript meetup, but everybody. Our bosses, our families, our friends. We must be humble, we must be responsible, we must be kind. And we must open our doors and our minds to people who don’t look like us, don’t talk like us, don’t think like us – because if the code we write is going to change the world, then we’re going to need the whole world to help us understand, and manage, the cost of that code.

Thank you.

{kind=link}
{kind=link}
{kind=link}